Anthropic이 Claude Sonnet 5 ↗를 공개했습니다. 발표문에서 가장 눈에 띄는 표현은 “가장 agentic한 Sonnet 모델”입니다. 단순히 답변 품질이 오른 모델이 아니라, 계획을 세우고, 브라우저와 터미널 같은 도구를 쓰고, 여러 단계를 이어가며 작업을 끝까지 처리하는 모델이라는 점을 전면에 내세웠습니다.
먼저 결론부터 말하면, Sonnet 5는 Opus를 대체하는 최고급 모델이라기보다 Sonnet의 역할을 다시 정의하는 모델입니다. 이전의 Sonnet이 빠르고 실용적인 범용 모델이었다면, Sonnet 5는 Claude Code, 업무 자동화, 브라우저·터미널 기반 작업을 맡길 수 있는 기본 실행 모델에 가깝습니다.
이 글에서 다루는 내용:
- Sonnet 5가 기존 Sonnet과 무엇이 다른가
- effort 조절이 모델 선택과 비용 계산을 어떻게 바꾸는가
- Claude Code 같은 코딩 에이전트에서 왜 의미가 큰가
- 가격, tokenizer, 안전성 평가에서 주의할 점은 무엇인가
Sonnet의 역할이 바뀝니다
Sonnet 라인은 원래 Claude 제품군에서 성능과 비용의 균형을 맡는 모델입니다. Claude 모델 문서 ↗는 Claude Sonnet 5를 “speed and intelligence”의 조합이 좋은 모델로 설명하고, Claude API ID를 claude-sonnet-5로 안내합니다.
이번 발표의 핵심은 이 균형점이 단순 채팅이나 코드 생성이 아니라 에이전트 실행 쪽으로 이동했다는 점입니다. Anthropic은 Sonnet 5가 Sonnet 4.6보다 reasoning, tool use, coding, knowledge work에서 개선됐고, 성능은 Opus 4.8에 가까우면서 가격은 더 낮다고 설명합니다.
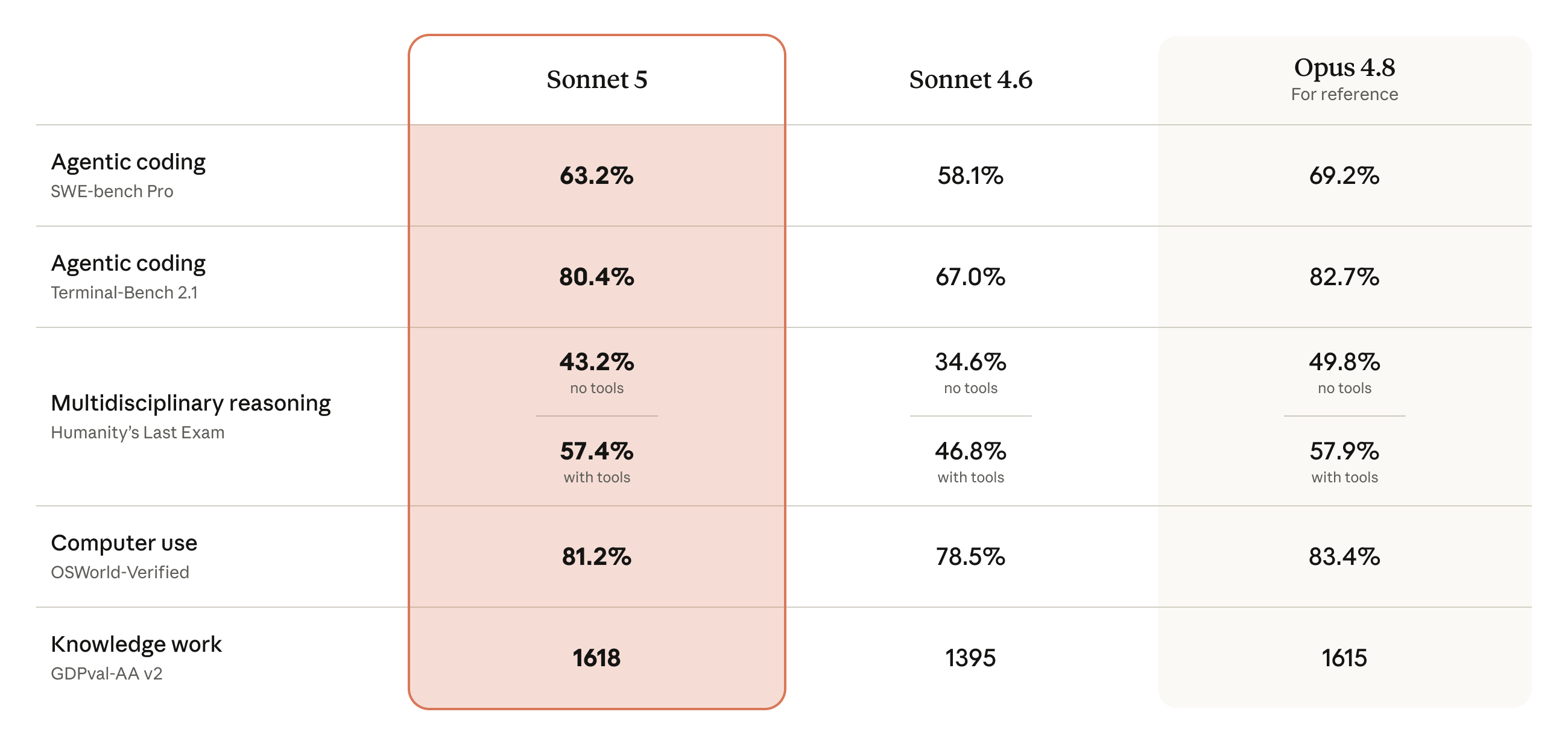
공식 발표의 benchmark 표는 Sonnet 5의 위치를 잘 보여줍니다. Opus 4.8이 여전히 더 강한 기준점으로 남아 있지만, Sonnet 5는 Sonnet 4.6보다 전반적으로 높은 점수를 보이며 knowledge work에서는 Opus 4.8과 거의 같은 수치를 보입니다.
기존 Claude Sonnet 4.6이 “중간 모델도 Opus급 성능에 접근할 수 있다”는 신호였다면, Sonnet 5는 그 방향을 에이전트 작업으로 더 밀어붙입니다. 반대로 Claude Opus 4.8이 복잡한 판단과 장시간 작업의 상위 선택지라면, Sonnet 5는 더 많은 일상 에이전트 워크플로의 기본값이 될 수 있습니다.
핵심은 agentic 실행력입니다
Anthropic은 Sonnet 5가 계획을 세우고, 도구를 사용하고, 이전 Sonnet 모델보다 복잡한 작업을 더 끝까지 수행한다고 설명합니다. 초기 파트너 피드백도 “이전 모델은 중간에 멈추던 일을 Sonnet 5는 끝까지 처리한다”는 쪽에 모입니다.
개발자 관점에서 이건 중요합니다. 실무 코딩에서 가치는 코드를 한 번에 많이 쓰는 데서 나오지 않습니다. 실패를 재현하고, 원인을 좁히고, 기존 코드 관례를 따르고, 테스트로 확인하고, 변경의 부작용을 줄이는 데서 나옵니다.
flowchart TD
A["작업 요청"] --> B["계획 수립"]
B --> C["파일·문서 탐색"]
C --> D["도구 호출"]
D --> E["코드 수정"]
E --> F["테스트·검증"]
F --> G{"문제 남음?"}
G -->|예| C
G -->|아니오| H["결과 보고"]이 흐름에서는 순수 벤치마크 점수보다 “작업을 중간에 놓지 않는가”, “도구 호출을 과하게 낭비하지 않는가”, “검증까지 자연스럽게 가는가”가 더 중요합니다. Claude Code 품질 포스트모템에서 다뤘듯이 코딩 에이전트의 체감 품질은 모델 가중치만이 아니라 reasoning effort, 컨텍스트 관리, 제품 레이어의 기본값에 크게 좌우됩니다.
effort가 모델 선택 방식을 바꿉니다
Sonnet 5에서 특히 봐야 할 부분은 effort ↗입니다. effort는 Claude가 응답에 얼마나 많은 토큰과 작업량을 쓸지 조절하는 파라미터입니다. Anthropic 문서에 따르면 이 값은 텍스트 응답뿐 아니라 tool call과 function argument까지 포함한 전체 응답 토큰 사용에 영향을 줍니다.
Sonnet 5는 기본값이 high effort입니다. 문서는 xhigh를 가장 어려운 코딩·에이전트 작업에, medium을 기본값보다 비용을 줄이는 선택지에, low를 대량 처리나 지연 시간에 민감한 작업에 권장합니다.
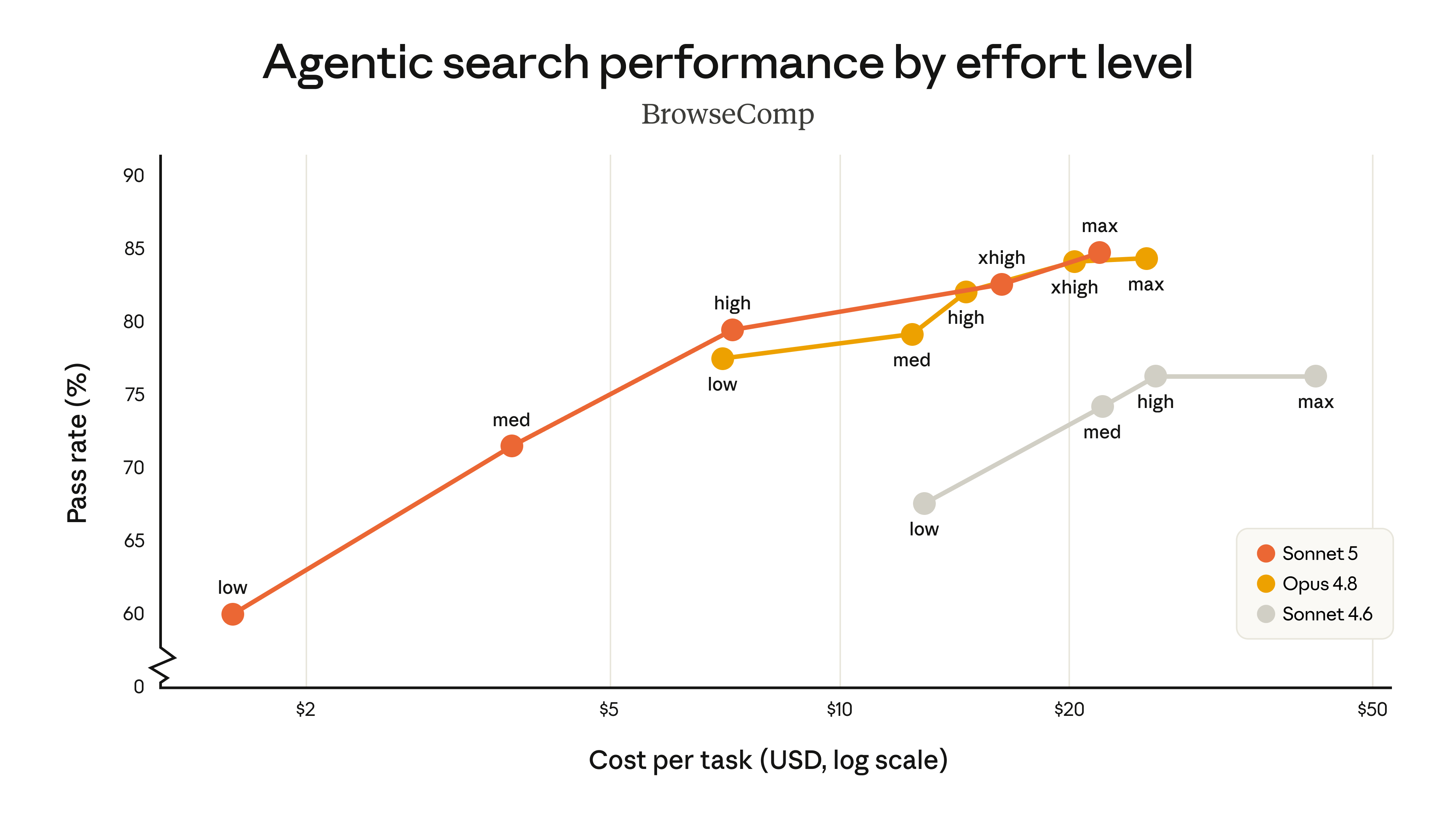
공식 차트에서 Sonnet 5는 BrowseComp 기준으로 낮은 effort부터 높은 effort까지 넓은 비용-성능 구간을 만듭니다. 특히 중간 effort 구간에서 Sonnet 4.6보다 높은 성능을 보이면서도 Opus 4.8보다 낮은 task cost 영역을 차지합니다.
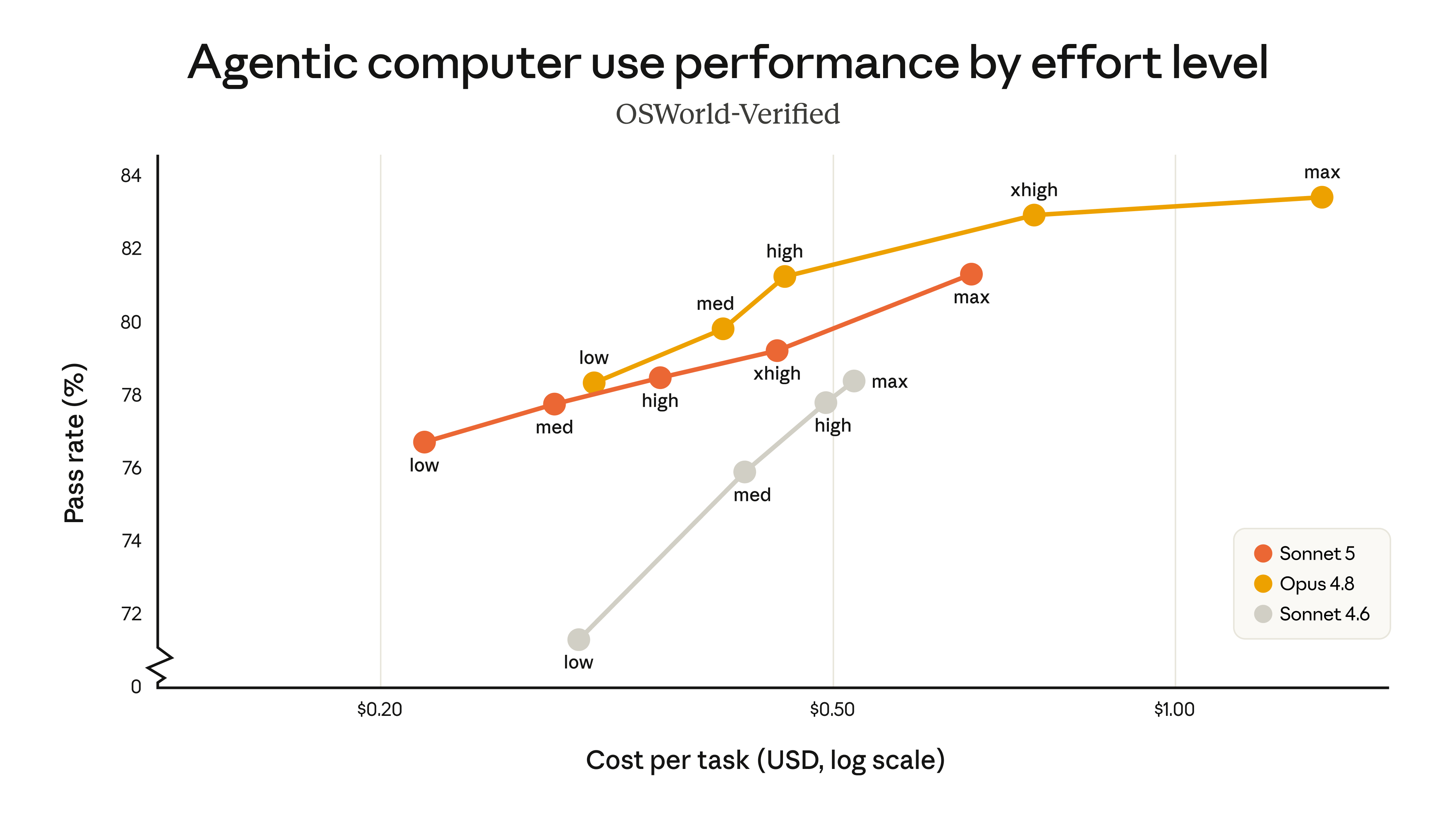
OSWorld-Verified 차트에서는 Opus 4.8이 최고 성능을 유지하지만, Sonnet 5가 Sonnet 4.6보다 낮은 비용 구간에서 더 높은 pass rate를 보입니다. 이 차이가 Claude Code 같은 도구에서 “기본 실행 모델”로서의 의미를 만듭니다.
| effort | Sonnet 5에서 어울리는 작업 |
|---|---|
low | 짧은 채팅, 단순 요약, 대량 서브태스크 |
medium | 비용을 줄이고 싶은 일반 에이전트 작업 |
high | 기본값. 복잡한 추론, 코딩, 도구 사용 작업 |
xhigh | 긴 코딩 작업, 장시간 agentic workflow |
max | 비용 제약보다 최대 성능이 중요한 작업 |
예전에는 “중요한 일은 Opus, 일상 작업은 Sonnet”처럼 모델 등급을 고르는 느낌이 강했습니다. 이제는 같은 Sonnet 안에서도 작업 단위별로 effort를 올리거나 낮추며 비용과 품질의 균형을 잡는 방식이 더 자연스러워집니다.
{
"model": "claude-sonnet-5",
"effort": "high"
}위 값들은 Claude 모델 문서 ↗의 API ID와 effort 문서 ↗의 effort level을 기준으로 한 예시입니다. 실제 API 호출에서는 사용 중인 SDK와 Messages API 형식에 맞춰 요청 본문을 구성해야 합니다.
low나 medium, 코드베이스 수정과 검증은 high 이상처럼 나누면 비용 추적이 쉬워집니다.
가격은 introductory pricing과 tokenizer를 같이 봐야 합니다
Anthropic 발표에 따르면 Sonnet 5는 Claude 앱의 Free와 Pro 플랜에서 기본 모델로 제공되고, Max, Team, Enterprise에서도 사용할 수 있습니다. Claude Code와 Claude Platform에서도 제공됩니다.
API 가격은 2026년 8월 31일까지 introductory pricing으로 백만 입력 토큰당 2달러, 백만 출력 토큰당 10달러입니다. 이후에는 백만 입력 토큰당 3달러, 백만 출력 토큰당 15달러로 이동합니다. Claude 모델 문서 ↗의 최신 모델 비교 표도 Sonnet 5의 표준 가격을 입력 3달러, 출력 15달러로 안내합니다.
| 구분 | 입력 100만 토큰 | 출력 100만 토큰 |
|---|---|---|
| 2026-08-31까지 introductory pricing | $2 | $10 |
| 이후 표준 가격 | $3 | $15 |
다만 가격표만 보고 기존 Sonnet과 단순 비교하면 실제 비용 감각이 어긋날 수 있습니다. Anthropic은 Sonnet 5가 업데이트된 tokenizer를 사용하며, 같은 입력이 콘텐츠 유형에 따라 대략 1.0~1.35배 토큰으로 계산될 수 있다고 설명합니다. introductory pricing은 이 전환을 대체로 비용 중립적으로 만들기 위한 장치입니다.
안전성 평가는 좋아졌지만 운영 경계는 더 중요해집니다
Anthropic은 Sonnet 5가 Sonnet 4.6보다 악성 요청 거부, 프롬프트 인젝션 저항, 환각, sycophancy 측면에서 개선됐다고 설명합니다. 자동 행동 감사에서도 Sonnet 4.6보다 전반적으로 낮은 misaligned behavior를 보였다고 합니다.
하지만 이 말이 “항상 더 안전하다”는 뜻은 아닙니다. 발표문은 Sonnet 5가 Opus 4.8이나 Mythos Preview보다 일부 평가에서 더 높은 misaligned behavior를 보였다고 함께 밝힙니다.
사이버 보안 쪽 설명도 조심스럽습니다. Anthropic은 Sonnet 5를 의도적으로 사이버 보안 작업에 훈련하지 않았고, Firefox 취약점 exploit 평가에서 두 Sonnet 모델 모두 완전한 working exploit 개발에는 성공하지 못했다고 설명합니다. 다만 Sonnet 5가 Sonnet 4.6보다 부분 성공률은 조금 높아졌기 때문에, 실시간 cyber safeguards를 기본으로 켰다고 합니다.
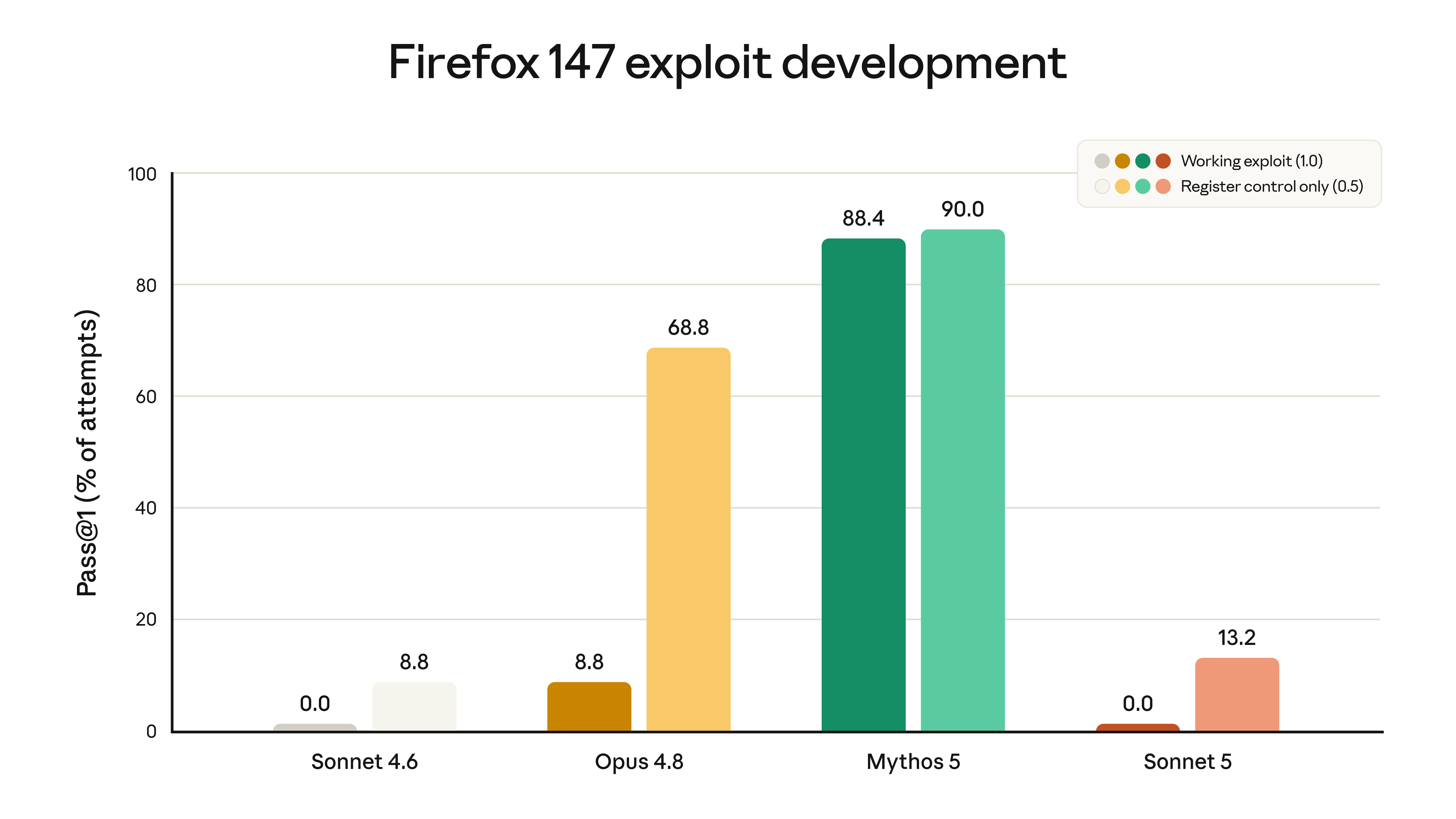
이 차트에서 Sonnet 5는 working exploit 개발에는 성공하지 못했지만, register control 수준의 partial success는 Sonnet 4.6보다 높게 나타납니다. Anthropic이 Sonnet 5에 cyber safeguards를 기본 적용했다고 설명하는 배경입니다.
이 대목은 에이전트 모델의 딜레마를 잘 보여줍니다. 일반 지능과 도구 사용 능력이 올라가면 정상적인 개발·자동화 능력도 좋아지지만, 악용 가능성도 일부 같이 올라갑니다. 그래서 Claude Code 같은 환경에서는 프롬프트 인젝션, 권한 경계, 로그 검토, 도구 제한이 점점 더 실무 이슈가 됩니다.
Claude Code에서는 무엇을 기대할 수 있나
Claude Code에서 모델은 채팅 상대가 아니라 작업자에 가깝습니다. 파일을 읽고, 명령을 실행하고, 실패 로그를 보고, 다시 수정합니다. Sonnet 5의 개선 방향은 이 흐름과 잘 맞습니다.
기대할 수 있는 변화는 세 가지입니다.
- 긴 디버깅과 테스트 작성에서 중간 포기가 줄어들 가능성이 큽니다.
high와xhigheffort를 작업 성격에 맞게 나누면 비용과 품질을 더 세밀하게 조정할 수 있습니다.- Sonnet급 가격대에서 Opus에 가까운 에이전트 성능을 쓸 수 있다면, 더 많은 작업을 기본 모델에 맡길 수 있습니다.
다만 무조건 Sonnet 5 하나로 통일하는 전략은 성급합니다. 아주 복잡한 판단, 긴 비동기 작업, 실패 비용이 큰 변경은 여전히 Opus급 모델이나 더 강한 검증 절차가 필요할 수 있습니다. 반대로 단순 정리, 짧은 요약, 대량 서브태스크는 Sonnet 5의 낮은 effort 또는 더 가벼운 모델이 나을 수 있습니다.
마무리
Claude Sonnet 5는 화려한 데모용 모델이라기보다 AI 에이전트를 일상 업무에 붙이는 팀들이 바로 비용 계산을 해볼 만한 모델입니다. Opus급 성능에 가까워지면서도 Sonnet급 가격대를 유지하려는 시도이고, Claude Code 같은 개발 도구에서는 그 의미가 특히 큽니다.
이제 중요한 질문은 “모델이 코드를 잘 쓰는가”에서 “모델이 일을 끝까지 맡아도 되는가”로 옮겨가고 있습니다. Sonnet 5는 그 질문에 대한 Anthropic의 새 답변입니다.
관련 글도 함께 보면 흐름이 더 선명합니다.
- Claude Sonnet 4.6 심층 분석 — 이전 Sonnet 세대가 Opus급 성능에 접근했던 흐름
- Claude Opus 4.8 출시 — 더 복잡한 판단과 장시간 에이전트 작업의 상위 선택지
- Claude Code 품질 포스트모템 — 모델 체감 품질이 effort와 제품 기본값에 흔들리는 이유